
How Much Knowledge Work Can Biopharma Offload To AI? Answer: Not Much
By Richard Moroney, Ph.D., Stat Consulting

Artificial intelligence (AI) is all the rage right now; it seems like it is taking over every discussion in feeds today. So here I am, adding to the noise! From my viewpoint as a consultant for the last two decades, I am specifically interested in exploring how this new capability is going to transform the world of biological manufacturing and process control.
Hopefully, with an understanding of where the industry is heading, we can all plan for successful business adaptation going forward.
Let’s begin with some definitions and frameworks for the conversation. Specifically, let’s first agree on a definition of intelligence independent of AI and how that links to things we measure and care about. Then we will look at different kinds of work we do and how features of the work may be impacted separately. Once that foundation is set, we will look more closely at our industry and where we are headed.
Intelligence Defined
A basic definition of intelligence might be “the ability to acquire, understand, and use knowledge.” This highlights how intelligence is more a process for us than any specific end goal. Building on this, then, we could define AI as “the ability of an inorganic system to acquire, understand, and use knowledge.” This definition will help us recognize that, for our purposes, AI is a process and much more general than just the large language models and image manipulations that are generating so much of the news cycle content.
We should (and I will) include tools like Big Data and machine learning within the AI tent. Indeed, I suggest all of the tools going into the digitization of quality systems (known generally as Quality 4.0) at least loosely fit within the same tent. Clearly, there can be good discussion on that point, and some may suggest I have gone a bit too far. But the key point I want to make is probably more agreeable: the changes being thrust upon us by new AI tools are not as new or as scary as they might initially appear. After all, those of us focused on production quality have been engaged with this type of transformation activity for our entire careers.
So, here we want to focus on how AI will help us acquire, understand, and use knowledge. To make this useful, we now need to define knowledge more carefully. I have used a simple model for this in my work over the last two decades, comprising a hierarchy of data, information, knowledge, and wisdom as sketched in Figure 1.
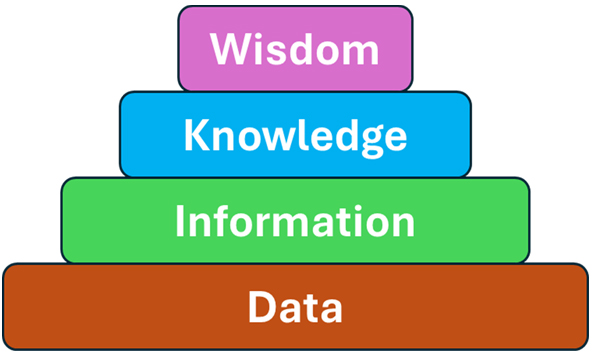
With this hierarchy in mind, we can now provide specific definitions for each element. Starting from the bottom:
- Data is one or more observations made within a clearly agreed context. Because of this, data can be considered as universally true. For example, a temperature sensor in a bioreactor might read 38.1 C and a second probe at a different location reads 36.9 C. Anybody looking at these two monitors will agree with each of these observations.
- Information is a set of related data collected and organized by a clearly agreed process. Because of this, information is not universally true, but the process used can be universally understood. For example, the two temperature probes each have specific sensors and circuitry used to estimate temperature at their location. Anybody looking in detail at these devices can add additional contextual data to the discussion, such as, for example, by estimating the response time of each monitor (which may or may not be the same).
- Knowledge is some amount of related information woven together into a coherent and larger story. Since information isn’t perfect, knowledge won’t be either and therefore it can’t be universally true. This is the first level where skepticism of what others are saying can reasonably be brought up, but as knowledge builds up, the skepticism is normally reduced. Knowledge is like a blanket woven from threads of information: it looks whole on first glance, but it can be threadbare in places, and if you look close enough there are holes everywhere. For an example at this level, matching our understanding of temperature control in the bioreactor with oxygen levels, pH, agitation, and other parameters gives us some level of confidence in our process status and control state. We might agree on all of the probe locations and sensor readings from the data and information levels but still have differences of opinion on how well the collection is reporting status and facilitating our control.
- Wisdom is ultimately created by gathering and reviewing enough knowledge so we eventually see patterns and possibly reveal the bigger picture of the system’s performance. As with knowledge, there may be significant skepticism when we share different ideas of wisdom. My blanket of gathered knowledge is no longer a thin piece of fabric but is now a complex shape that is warm and cozy, thick and fluffy on one side (for warm days) and wooly on the other (for cold days). We are frequently skeptical of other people’s wisdom, as ideas at this level can appear very strange to an outsider, so we need to accept that others may be skeptical of ours; this is normal, as all wisdom requires a bit of faith. In the bioreactor example, we might demonstrate our wisdom when extending the system’s performance beyond the current conditions, such as during scale-up of the batch size, transfer of the process to a new site, or validating a new product. As much as we work to standardize these types of processes, there is still significant art left in the work that tends to make each situation unique in some way.
As a summary of this hierarchy, we all agree on the data observations, we all understand how the information was obtained, we all reach similar places (eventually) on the range of understood knowledge, and we all put a significant amount of our own faith into wisdom. This discussion has been very linear, but generally the knowledge generating process is full of feedback: my view of wisdom will shape questions I ask to build more information and knowledge and also which pieces of data I even consider. This can be a source of bias. But as a point of reference, we can all agree on the data we use, and we can all understand the information we share (even if we have open concerns that prevent agreement).
With this foundation and a definition of AI as “the ability of an inorganic system to acquire, understand, and use knowledge” let’s focus the rest of this discussion on knowledge work and the people who do knowledge work and how they will be impacted by advances in AI.
Knowledge Work Defined
Knowledge work is a term originally coined by Peter Drucker. It can be defined as “the process of creating or deploying knowledge” as knowledge was defined in the hierarchy described above. It’s key to recognize here that knowledge work generally does not have a single possible outcome — part of the work is to decide which specific outcome is best in any given specific situation. Most work we think of as leadership or management responsibilities would initially be classified as knowledge work, as would most decision-making tasks.
As an example, a business strategy is the output of knowledge work. We might invest in new products to better serve our current customers, adapt our existing products to find new customers, or acquire another business to expand our capabilities. All of these approaches have worked for business in the past and are probably reasonable to consider. But which choice is best for us going forward at this specific time? The answer will depend on your current situation in the market, your vision for the future of your business, and your risk tolerance, to name just a few of the factors to be considered in the decision.
We can contrast knowledge work with manual work. Most work we think of that is not management would initially be classified as manual work: a store clerk, a sales representative, or an operator on the manufacturing line for example. Henry Ford, when he simplified and standardized assembly line work to improve efficiency, was focused more on manual workers than knowledge workers (although these terms were not in use at the time).
This distinction is not as black and white as these definitions suggest, so let me describe by example a few of the nuances here.
Consider the cleaning and testing of sterility in an aseptic processing facility. The first role to consider is the actual cleaning of the environment, which is manual work. The cleaning will follow a clearly defined procedure that may change in detail from day-to-day. This task is critical, it is likely to be fairly complicated, and the technicians doing the work will be skilled and well trained for the task. The operators will document the cleaning has been completed once finished and then move onto other activities. It is unlikely that any objections will be raised about the completion of cleaning at this time unless they directly relate to the procedure (e.g., a step was missed or the wrong tool or solution was used). These are all characteristics of manual work: it may be complicated but will be driven by a procedure and it generates data during that procedure to confirm it has been completed properly.
Next, consider the periodic testing of the aseptic environment, which is fundamentally knowledge work. The key deliverable of this testing should be confidence that the aseptic environment has not been compromised and that any produced products are free of contamination. This, of course, is a very difficult question to answer. Over years of experience and experimentation we have learned much about sources of contamination, detection methods, best practices, and effective operator training, but nobody would suggest they have all of the answers. We document and fix as much as we can, such as test locations, frequency of testing, incubation procedures, and analytical methods. When following these steps, the task will appear much like manual work up to the point of data generation.
Once we have the data, though, the work of testing the environment is not done. This data is frequently aggregated into some level of information about the aseptic environment. This might be a control chart, a time series, or another tool to look for possible trends in the data. The person responsible for the testing will review this information and make an assessment of the environment (and possibly also of the product being produced). They may additionally decide on procedure changes going forward (e.g., additional testing or cleaning) or raise questions for broader discussion (e.g., observations from the trend analysis). All of this information and recommendations will be reviewed with, at a minimum, the person accountable for the testing before the final determinations are agreed and documented. These are all characteristics of knowledge work: it may be driven by procedures in part, but the final determination is not simple to confirm and often relies on review and agreement by a group of people.
A similar comparison could be made for many other jobs, and it is worth noting that the knowledge work might be shared between different people. In sterilization of a medical device, for example, a device designer and a sterilization engineer would share in the key work of identifying locations for indicators to be used in the sterilization validation study. Or the fermenter operator might collaborate with the process owner to decide when to end the run and do a system cleanout and reset.
In my experience, every job will contain some parts of manual work and some parts of knowledge work. This is particularly true if you are working to improve your manufacturing process — the people doing the manual work on the line are usually the most valuable resource for identification of resistance issues when implementing a process improvement.
To conclude here, we recognize that manual work is reduced to a clearly defined process (e.g., SOPs and work instructions). The outcome may pass or fail, and we usually know the result fairly quickly once the task has been completed. We can always confirm that the correct activity and corresponding decision was done in the case of manual work. Knowledge work may have a guiding process (e.g., DMAIC for Six Sigma work), but the steps include one or more decision points that are essentially non-deterministic (e.g., planning an experiment or assigning relative weightings in a decision matrix). The outcome may pass or fail, though we may not know that result soon or at all. While we can confirm steps taken and the decisions made, there is always question of whether the selected activities and associated decisions of the knowledge work were complete and correct.
There is an analogy here, where we might see the relationship between manual work and knowledge work as similar to the relationship between verification and validation. Figure 2 shows a number of comparisons that roughly distinguish between verification and validation. Most of these dimensions are not a hard division of the two concepts, but they collectively help us get an idea of the difference. From the discussion above, we see how manual work is generally aligned with the features of validation, and knowledge work is generally aligned with the features of verification.
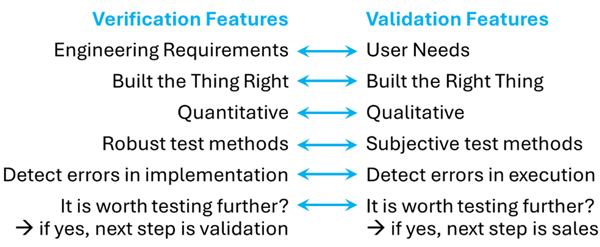
The analogy with verification and validation now directs our focus toward process improvement, specifically focusing on knowledge work.
Part 2 of this discussion digs into why I don’t believe AI will ever replace knowledge workers.
About The Author:
 Richard Moroney got his Ph.D. in electrical engineering from UC Berkeley and brings an additional 20 years of practical experience helping clients in pharmaceutical and medtech development and manufacturing. He specializes in debugging measurement and quality systems to ensure great decision-making (Six Sigma Black Belt) and ensuring your quality systems are not a burden on business (Certified Pharmaceutical GMP Professional). Richard has focused mostly on the statistics and data science aspects of Quality 4.0, with clients ranging from start-ups through Fortune 100, as well as the U.S. government. He founded Stat Consulting in 2024.
Richard Moroney got his Ph.D. in electrical engineering from UC Berkeley and brings an additional 20 years of practical experience helping clients in pharmaceutical and medtech development and manufacturing. He specializes in debugging measurement and quality systems to ensure great decision-making (Six Sigma Black Belt) and ensuring your quality systems are not a burden on business (Certified Pharmaceutical GMP Professional). Richard has focused mostly on the statistics and data science aspects of Quality 4.0, with clients ranging from start-ups through Fortune 100, as well as the U.S. government. He founded Stat Consulting in 2024.